History of PDF
The PDF format was originally specified and developed by John Warnock and his team at adobe in 1991. With this, they launched the paper to the Digital Revolution. PDF actually evolved from an existing page description language called postscript. Interestingly when PDF was created, its initial purpose was printing. It works great for printing because it scales without losing quality.
Today, it's ridiculous to even ponder that we can capture documents from any application, send electronic versions of those documents in exact fidelity to anywhere and view and print those documents on any machines. But this was still relatively early in the history of software, the age of incompatible operating systems and file formats. The World Wide Web was still years away from making its debut.
PDF in the 1980s
In the late 1980s, John Warnock and his colleagues at Adobe were trying to figure out the problem of creating a simple file format that could be used to print documents to a wide range of printers and view this printed information electronically. John Warnock was one of those technically brilliant dreamers who knew this common business problem, which could be solved by the right people and the right technology.

PDF in the 1990s
In the early 1990s, John Warnock proposed a solution in an internal adobe document and quietly gathered a small team to work on that project. Then they gave the code name to the project as the Camelot project, which quickly grew to become what we all know as adobe acrobat today. So two things were very clear in his mind.
First, there was a fundamental problem in worldwide business with being able to print documents to a wide range of printers, but no universal way to communicate and view this printed information electronically.
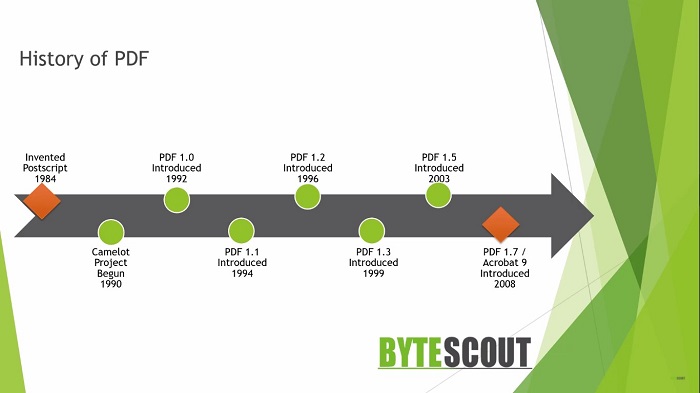
Second, he believed if the problem could be solved by adobe, the fundamental way people work will change. In 1984, John Warnock and his colleague had invented the postscript language. It is a standard page description language that is used in the electronic publishing and desktop publishing business. Postscript serialized page description commands so that a printing device could convert them into a printed page without big processors or a lot of memory.
In late May 1990s, Warnock met Randy Adams, who was one of the brilliant minds of Silicon Valley and shared his ideas for the Camelot project and asked him to do a UI demo and a technical proof of how the postscript and display postscript could potentially be utilized in solving the problem of universal document interchange. Randy Stiehm started brainstorming the new user interface concept required to pull together a universal reading and printing experience in an easy to use application.
Finally, on June 29, 1990, John Warnock saw his dream project Camelot come to life. In a small conference room, where he demonstrated the future user interface for viewing, printing, and working with electronic documents.

In 1992, the first version of PDF was officially announced at Comdex Fall, and Demo turned out to be a huge success. The development of a commercial version started first under the codename Camelot, although it was later renamed Carousel.
I have tried to show you the progress of different PDF versions in this timeline. Functional improvements were included in PDF files, starting with version 1.1, which was released in 1994. Improvements like it allowed external links, support for spot colors, support for plugins, etc.
PDF in the 2000s
In January 2008, PDF version 1.7 became officially ISO standard. From this point on, PDF is no longer remain a proprietary format. However, the team continued to develop the format, adding new features like editing form, functionality and web display, etc.
The ongoing development of a PDF now continues under the umbrella of ISO with the adopting acting in an advisory role and PDF evolves to these days, with new tools like support for e-signatures and the ability for users to work with the format on touch screens.
We at ByteScout offer a variety of options for working with PDF files. For example, if you copy the text, sometimes it is copied in a different order or it can't be copied at all or copied, but the copied text is damaged or even appears as garbage when you paste it.
All these issues are solvable with our various tools, such as PDF.co cloud API and on-premise tools like PDF Generator SDK, which will do a deep analysis of PDF files. We will see some of the use cases of these tools later on in this course. In the next session, we will study PDF internals and some PDF specifications in brief.
Web API for developers Free Trial Offline SDK
Here's video history of PDF:
Other useful articles:
- How to Extract Data from PDF
- Data Visualization
- Data Analysis
- Web Data Extraction
- Data Labeling
- Data Portability
- Brief Introduction of PDF Extractor SDK
- History of PDF
- Data Extraction Techniques
- Using Google Analytics for Data Extraction
- Data Extraction from PDF
- Data Extraction Software
- Using Python for Data Extraction from PDFs
- Web Scraping Tools to Save Time on Data Extraction
- Data Extraction Use Cases in Healthcare
- Data Extraction vs Data Mining
- Data Extraction and ETL
- TOP Questions about Data Extraction
- How Data Extraction Can Solve Real-World Problems
- Which Industries Use Data Extraction
- Types of Data Extraction
- Detailed Data Extraction Process
- TOP-5 Misunderstandings about Data Extraction