Brief Introduction of PDF Extractor SDK
In this session, we will be going to understand PDF Extractor SDK in brief. Since the PDF was first introduced in the early 90s, it shows the tremendous adoption rates and became a primary tool for record-keeping, communication, collaboration, and transactions across many industries in today’s time.
Our PDF Extractor SDK is good to go solution for extracting business data. It is a very advanced text extractor that automatically extracts data from PDF including scanned documents without any additional software required. Using this SDK we allow the developers to convert their PDF to Excel or JSON or CSV and so on.
How to Extract Structured Data
We at ByteScout really work hard to ensure development with the PDF Extractor SDK is the best experience possible. Now let’s see some of the features and benefits of this SDK. First, due to the high-performance engine, PDF Extractor SDK extracts millions of documents in a minute.
Extracting structured data from PDF documents and creating a smart index using this SDK allows you to search through millions of documents quickly. One can easily read or convert PDF documents of multiple language characters used in it. It works seamlessly with all character encodings. PDF Extractor can even process damaged files.
Sometimes PDF shows correct text but when you copy the damaged one you will not be able to paste it properly or you can't see that content. But this SDK repairs damage text even if it's not visible. One can easily merge or split documents using this SDK for easier management and you can convert your PDF document to excel, JSON, CSV, and so on.
With this SDK you can also protect your PDF from being copied or searched by converting the text content to an image. This converted file can retain not only the text but also the formatting fonts and colors. As we have already seen in the previous session, how PDF multi-tool can easily extract the text from scanned documents using AI-powered OCR.
Extract Text from Scanned Documents
In the same way, this SDK can also extract text from scanned documents resided within the PDF using a built-in OCR engine with multiple language support. The most powerful feature of this product is a mix of sophisticated technologies we use when developing the tools.
New sensitive data suite features are included in PDF Extractor SDK which analyzes, detects, and removes sensitive data and any personal information from the PDF doc. Dot net capabilities enable vast customization. We support dot net from 2.0 to the latest version.
This SDK works with the dot net, asp.net, and also available as ActiveX or com object through dot net interrupt wrapper for use from Delphi, VC++, javascript, and other languages. Finally, you will find a bunch of source codes and documentation that makes it easy to use this SDK.
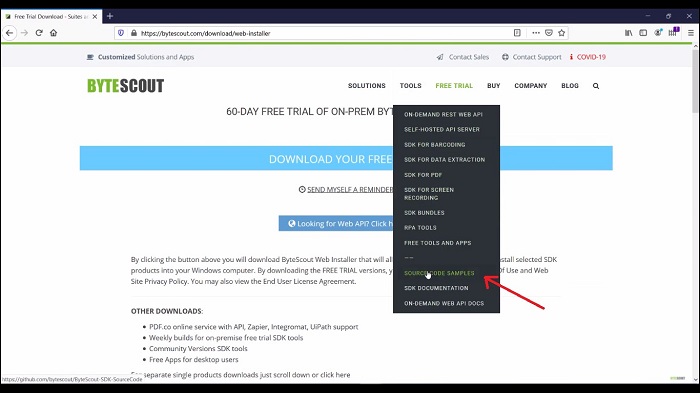
Our thousands of customers from different domains like healthcare, banking, logistics, insurance, finance use PDF Extractor SDK to automate manual document-based workflows. You can download this SDK from this URL. Let's open this URL and by clicking on this button you will download the ByteScout web installer that will allow you to select download and install selected SDK products into your machine. Once you download the SDK you can go through our SDK documentation or ready to copy-paste a source code sample that explains the functionality of each of these solutions.
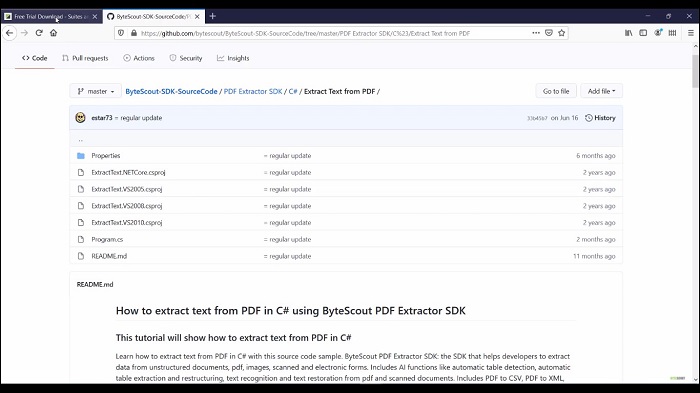
Work with Source Code Samples
Click on the source code sample which will redirect us to the GitHub website. Here you can find the sample source code of different SDK provided by ByteScout. Open our PDF Extractor SDK sample and we are providing pre-made source code samples for easy implementation in your own favorite programming languages like c sharp. Click on it and here you can find the sample source code of different use cases like detect lines in PDF, extract audio from PDF, extract images from PDF, extract PDF text to stream, and so on.
Once you click further, for example, extract text from PDF then you can see the sample code of different dot net versions. Now open the documentation of this SDK, that click on SDK documentation, and open PDF Extractor SDK documentation. Here in the left pane, you can find all the necessary information of this SDK from sample code to buying a license.
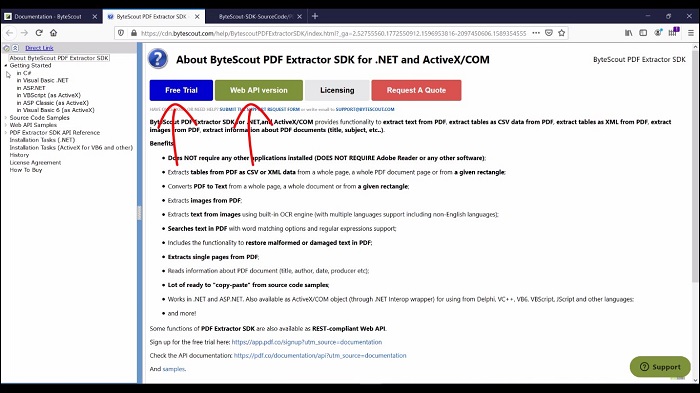
PDF Extractor SDK comes in two flavors, first, is the desktop-based which is an on-premise solution and the one is a web API based solution. PDF Extractor SDK is easily accessible through the API in c sharp, python and javascript, and many more languages. Their interactive API documentation explains the functionality of each of the endpoints.
Web API for developers Free Trial Offline SDK
Here's PDF Extractor SDK video tutorial:
Other useful articles:
- How to Extract Data from PDF
- Data Visualization
- Data Analysis
- Web Data Extraction
- Data Labeling
- Data Portability
- Brief Introduction of PDF Extractor SDK
- History of PDF
- Data Extraction Techniques
- Using Google Analytics for Data Extraction
- Data Extraction from PDF
- Data Extraction Software
- Using Python for Data Extraction from PDFs
- Web Scraping Tools to Save Time on Data Extraction
- Data Extraction Use Cases in Healthcare
- Data Extraction vs Data Mining
- Data Extraction and ETL
- TOP Questions about Data Extraction
- How Data Extraction Can Solve Real-World Problems
- Which Industries Use Data Extraction
- Types of Data Extraction
- Detailed Data Extraction Process
- TOP-5 Misunderstandings about Data Extraction